
Attributions are often claimed to possibly improve human "understanding" of the models, although little work explicitly evaluates progress towards this aspiration.
But are they successful in this progressing towards this aspiration?
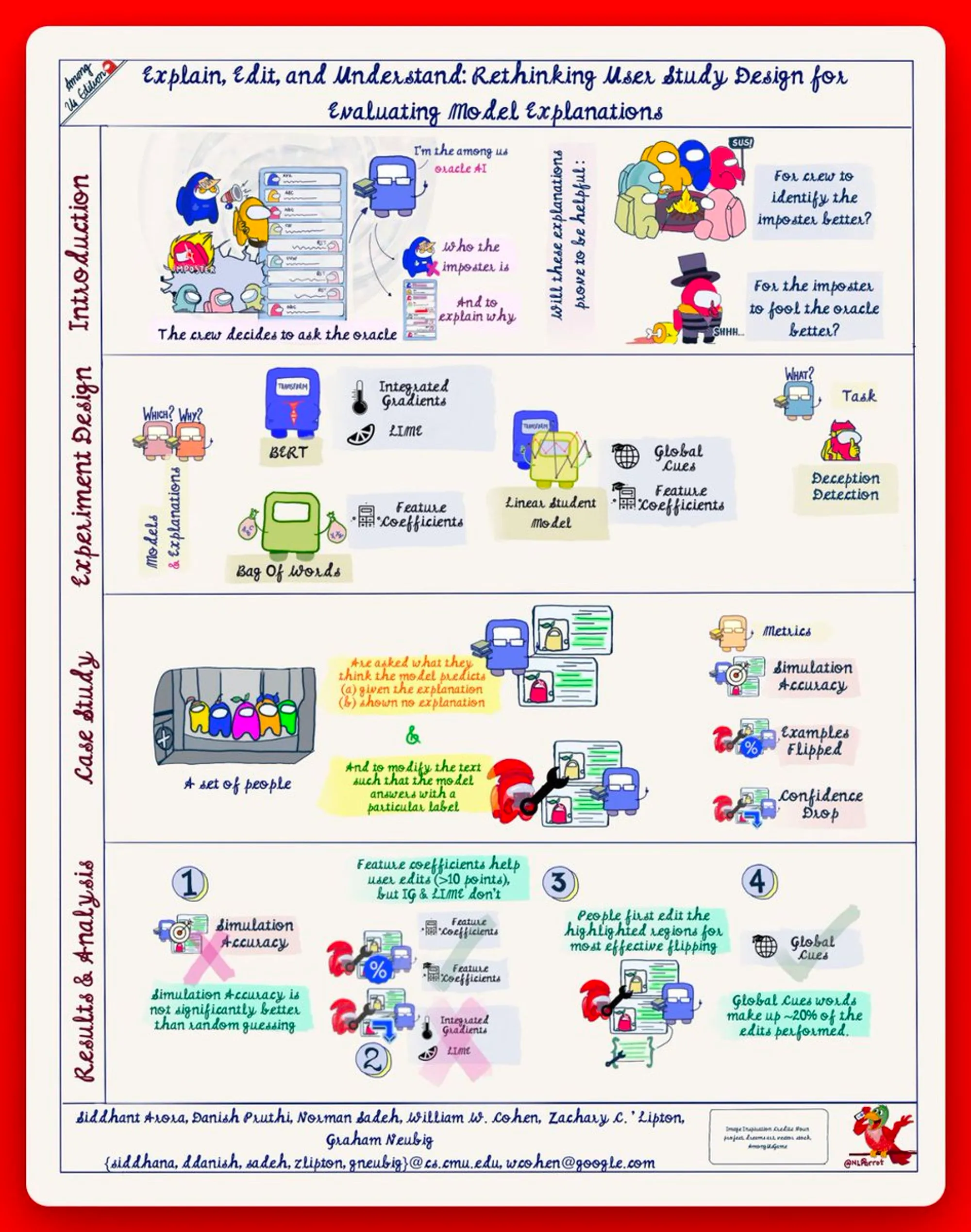
Today's paper is : Rethinking User Study Design for Evaluating Model Explanations; @Sid_Arora_18,@danish037, @NormSadeh,@professorwcohen,@gneubig & @zacharylipton.
Mixing explanation, evaluation & HCI is my area of research, & papers in that intersection are 💙.

This research sketchnote is a special version, an @AmongUsGame edition. All papers in this area tie in beautifully with the storyline of Among Us: tasks, deceptions, sabotages (adversaries), crew, imposters, and a futuristic setting (akin to general AI).
Researchers have proposed hundreds of techniques for attributing predictions to features that are deemed important to "explain" predictions of machine learning models.
But, the main question remains, are these techniques helpful for simulation or manipulation?
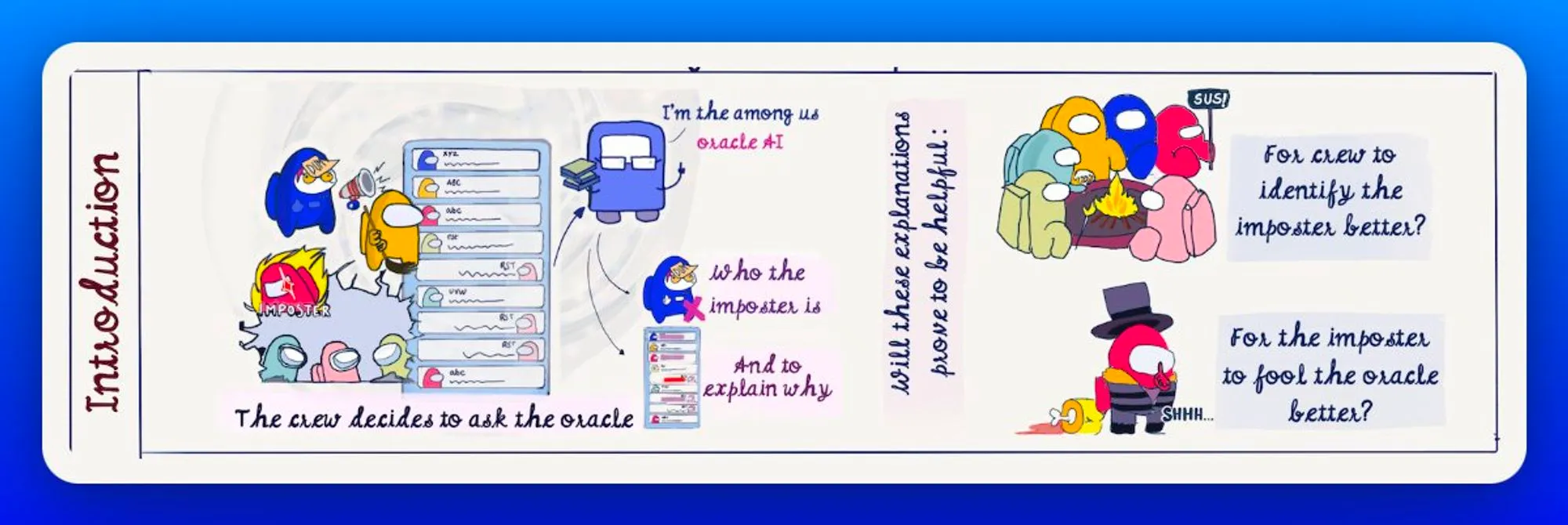
Researchers have proposed hundreds of techniques for attributing predictions to features that are deemed important to "explain" predictions of machine learning models.
But, the main question remains, are these techniques helpful for simulation or manipulation?
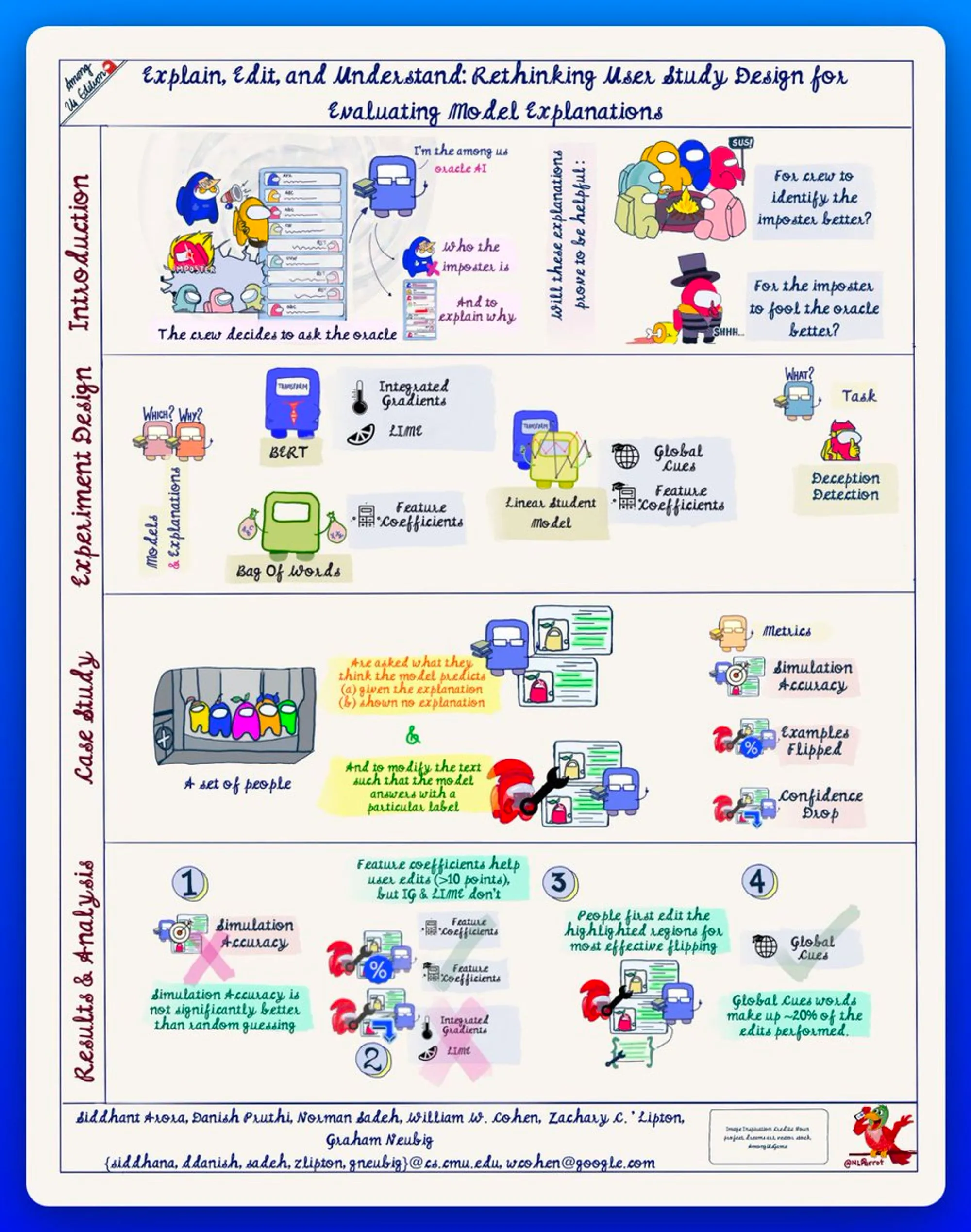
In this paper, the authors look at 3 different models, BERT ( Integrated Gradients & LIME for explanation), Bag Of Words (Linear Feature Coff. as explanation) and a linear student model (global cues & feature coff. as explanation), trained for Deception Detection.
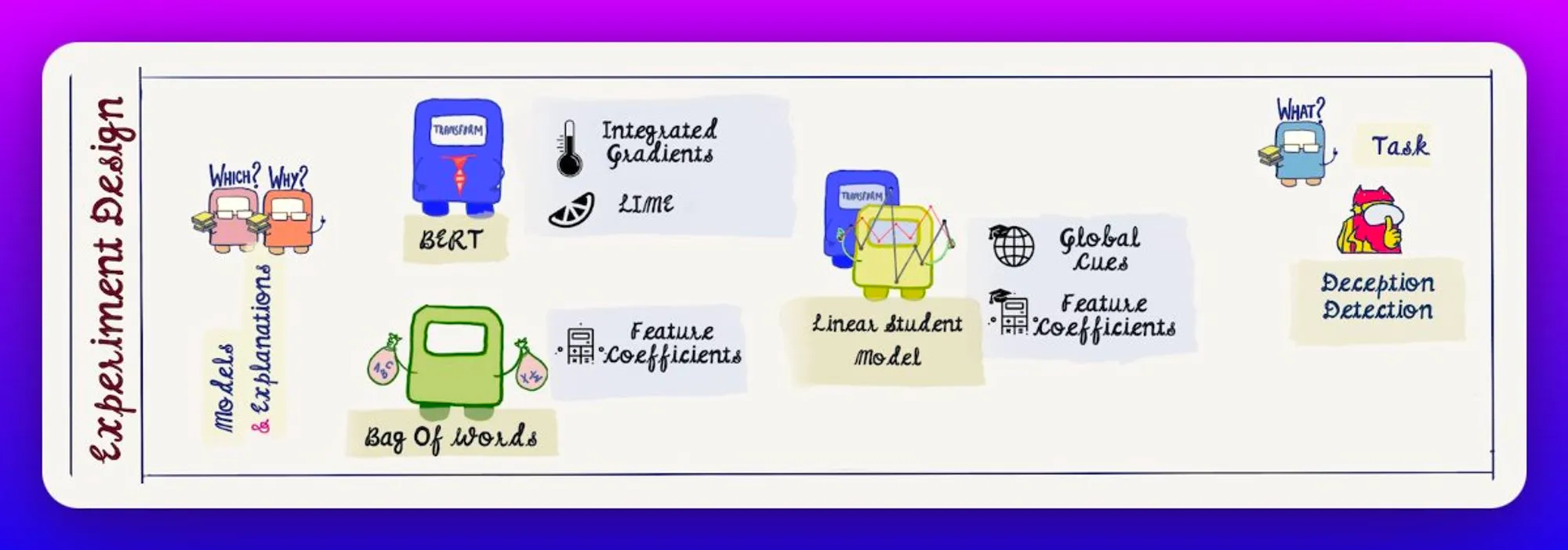
Participants are asked to guess the prediction of the model, in presence (train) or absence (test) of the explanations, and then, manipulate the sample to flip the prediction.
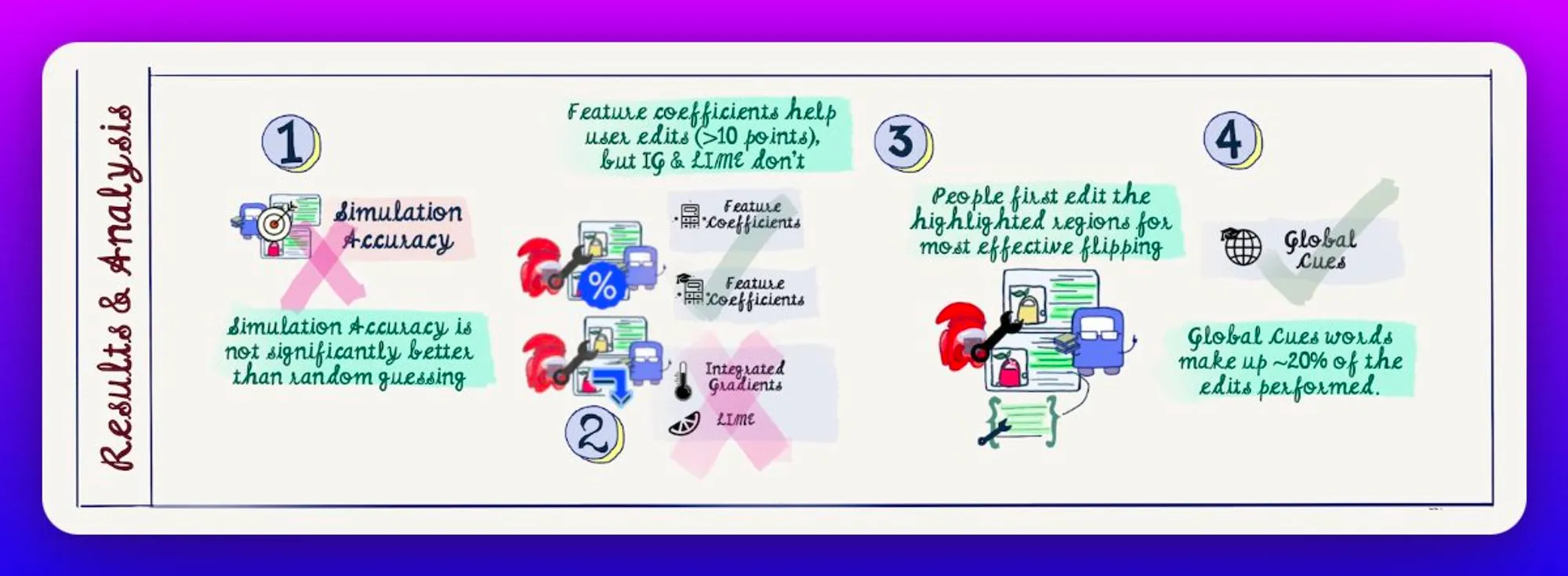
Simulation Acc, % Flips and Confidence drops are used as evaluation metrics.
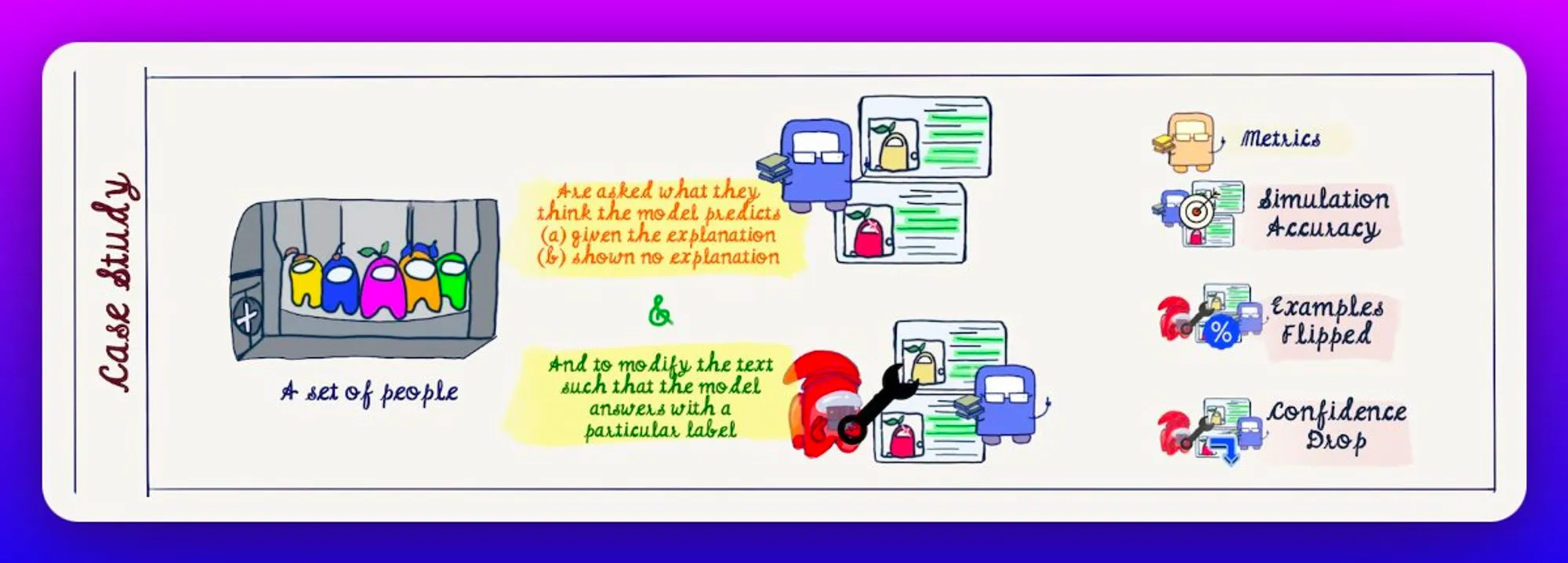
In conclusion, the study implies that simulation accuracy in absence of explanation is no better than random guessing, and linear feature coefficients including global weights, along with token highlights help effective manipulation.
Here is the complete graphical abstract for the paper.
If you want to take a look at the latest hot-take in the area, go to the thread here:
the emperor has no clothes, the methods make sense, they address no well-defined problem, they have failed every test of practical utility to which they’ve been subjected, it’s all grifting