
I know I said 2 papers a week, but well ADHD makes you hyper focus sometimes (sometimes? who am I kidding!). So, this weekend's paper is "Can Rationalization Improve Robustness?" by
@__howardchen, Jacqueline He, @karthik_r_n and @danqi_chen.


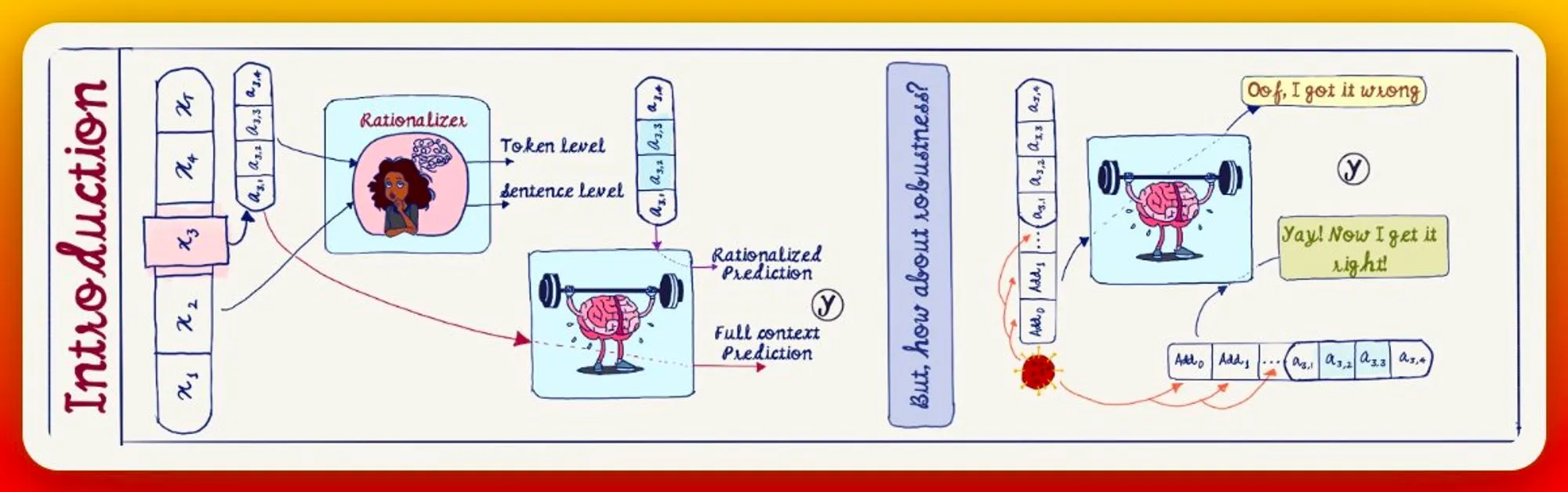
Model rationalizations can either on sentence levels or token level. A rationalizer can either be posthoc or be built in, into the model.
Robustness, on the other hand, is judged by how a model maintains its prediction in presence of adversarial text.
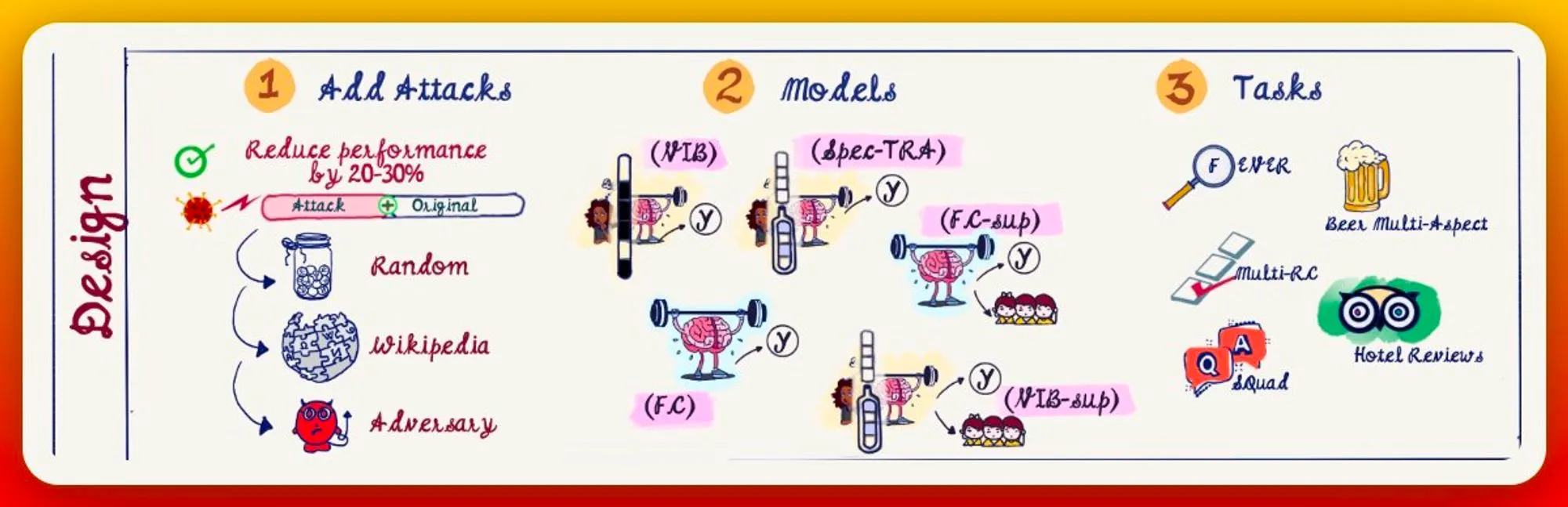
The experiment design takes into account (a) Text addition method, (b) Models, and, (c) Datasets.
Text addition can be random tokens, wikipedia sentences, or, specifically adversarial. Models can either just use the full context, have rationalizer modules, or supplemented.
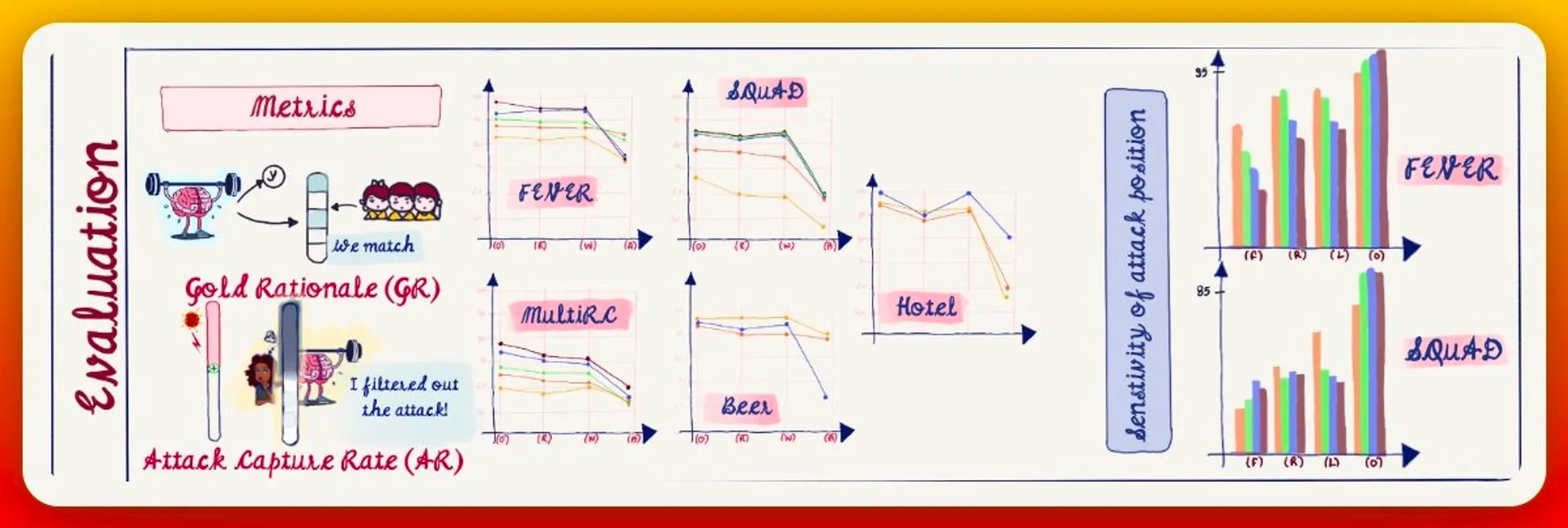
Robustness eval has 2 metrics: gold rationale, the equivalence to human rationale &, attack capture rate, efficiency at masking of attack information.
Models have different performance drops for different datasets, different adversarial additions & position of addition.
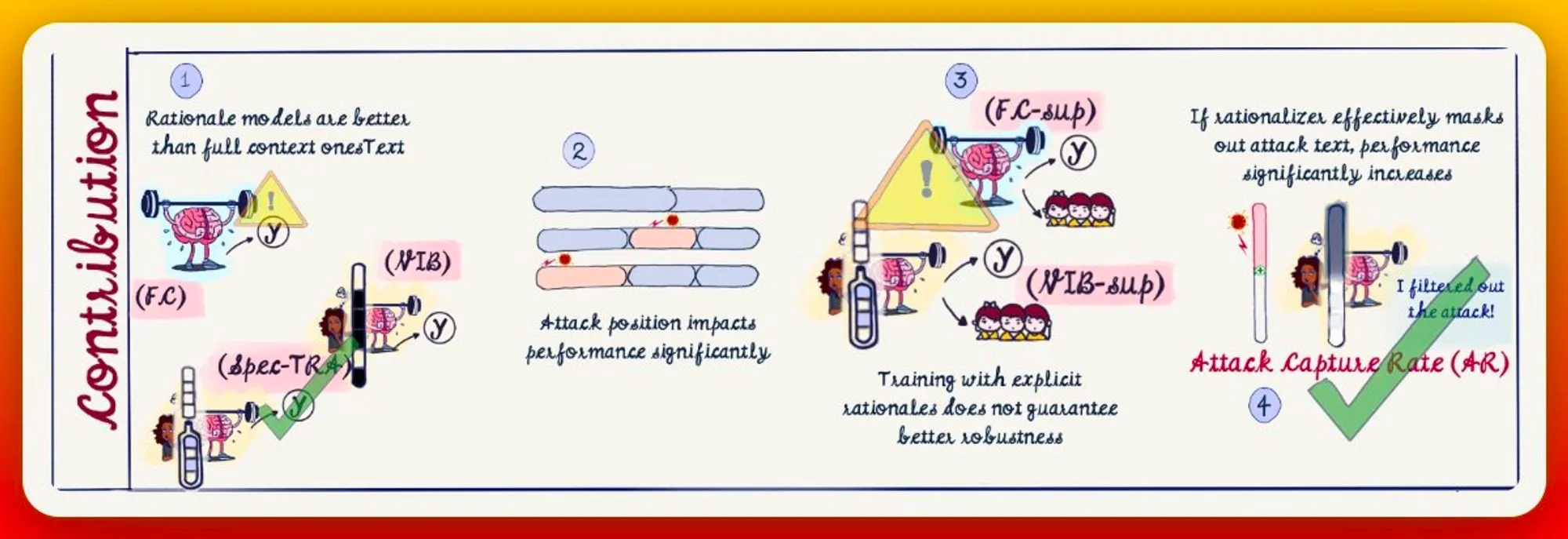
In summary,
(a) full context models are significantly less robust than those with rationalizer modules,
(b) position of adversarial text insertion matters,
(c) supplemented models maybe less robust, and,
(d) efficient masking implies improved performance.
Here is the complete graphical abstract for the paper.
