As I mentioned before, I am really glad to be able to merge my love for NLP with that of sketchnoting for science communication.
Today's paper is "Beware the Rationalization Trap!" by @RSevastjanova and @manunna_91
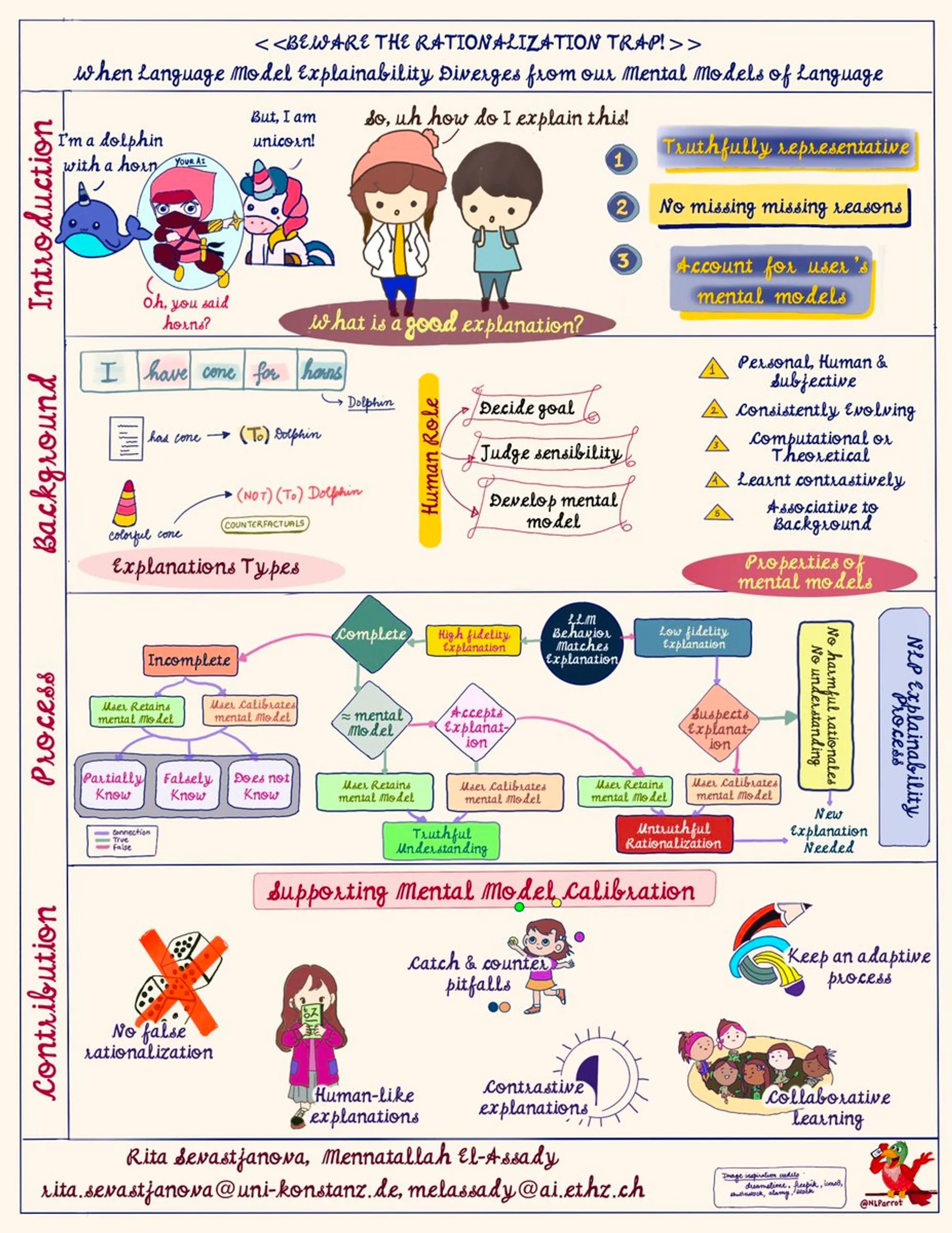
Explanations can either match or be on odds with any user's mental model. A good explanation should be truthful, have no missing reasonings, and account for the users' mental models.

Saliency, tuple & concepts are the main explanation types used, though, counterfactual explanations are preferred. Humans decide explanation goal, judge sensibility, &, develop mental models.
Mental models, amongst other things, should be personal, evolving & contrastive.

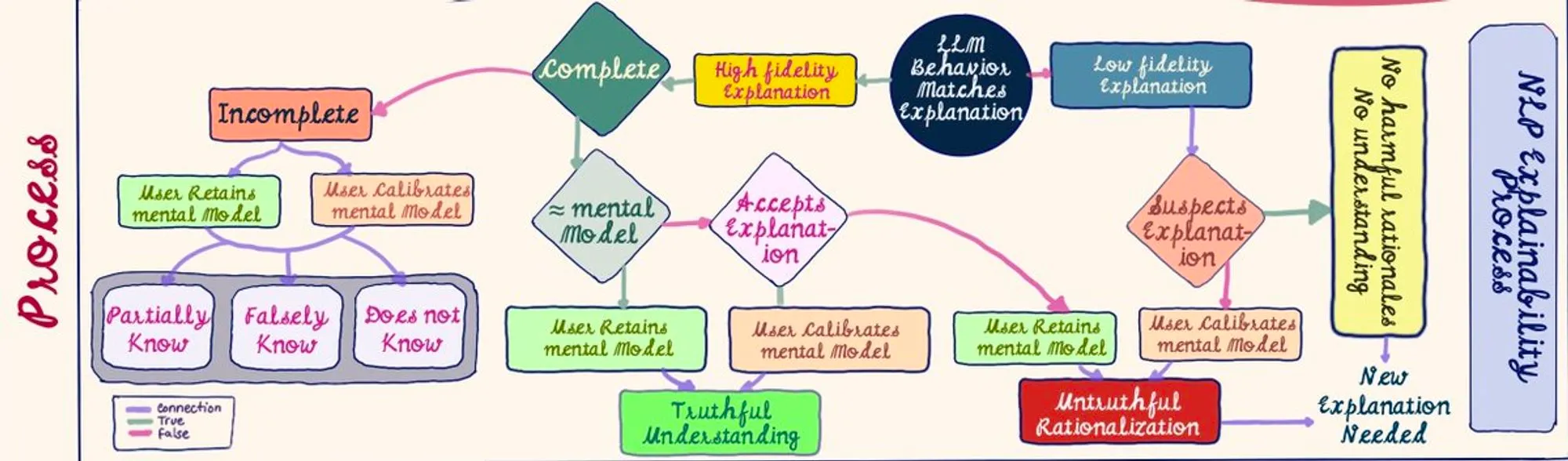
When comparing the explanation to the LLM's behavior, we either end up with high or low fidelity explanations. Depending on the alignment with a user's mental model, a person can leave with either a truthful understanding, an untruthful understanding, or no understanding.
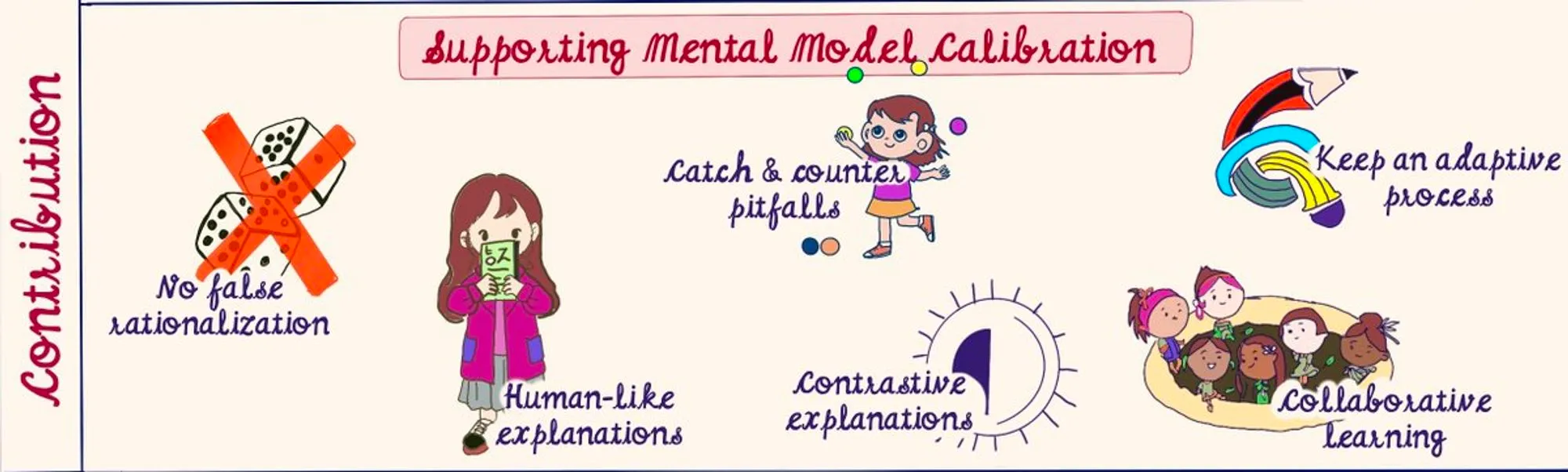
One of the main aims of any model explanation decision, should be supporting mental model calibration through: (a) no false generalization, (b) human-like explanations, (c) catch pitfalls, (d) contrastive explanations, (e) adaptive process, and, (f) collaborative learning.
Here is the complete graphical abstract for the paper.